摘要
前段时间,2023
贺岁纪念币的预约火热地进行着,当晚我也凭借惊人的手速抢到了 3 *20 = 60
个,某天偶然打开农行预约纪念币网的站,发现预约端口还未关闭,便想着用
Selenium 自动化测试来实现全自动预约纪念币。
本文使用的技术包括但不仅限于:Python、Selenium-Python、OCR、CNN、Android
adb
声明:本文只用于技术分享,禁止使用本文代码参与各种不当获利行为
Part I:基本 Selenium 自动化
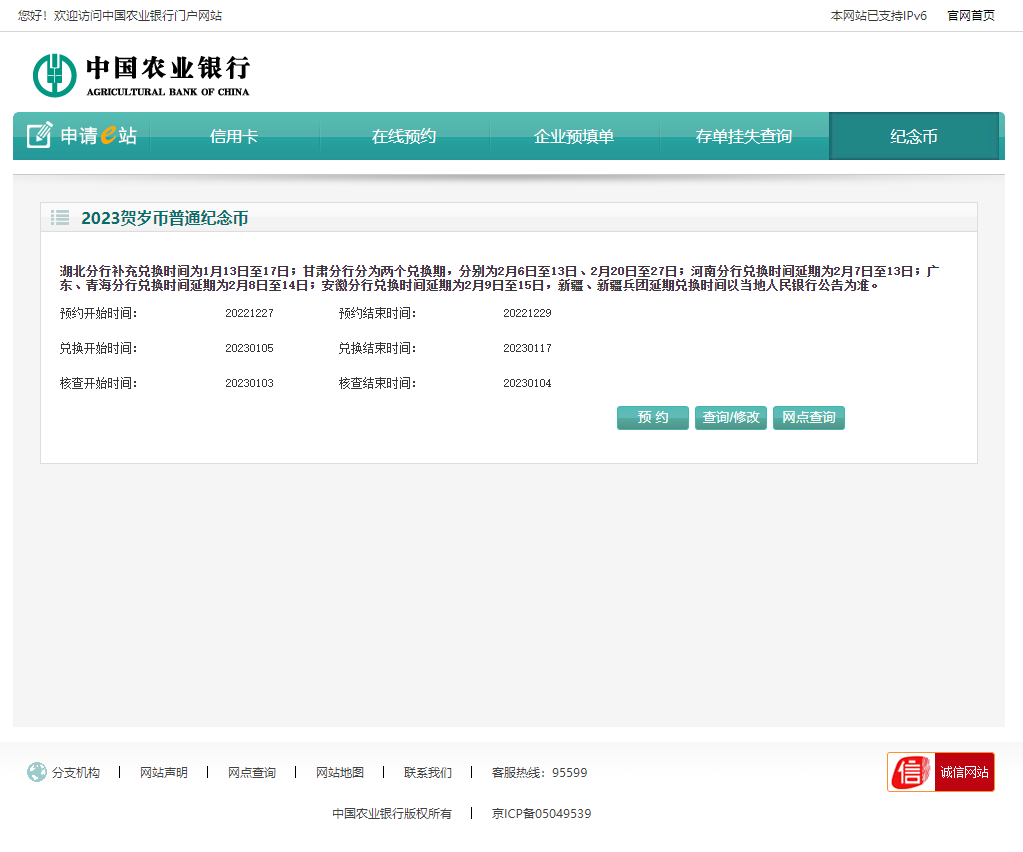
打开农行纪念币预约网址 ,进入纪念币预约,可见布局如下:
welcome_page
接下来就是基本的 Selenium
自动化了,F12打开开发者工具,查看 “ 预约 ” 的
Xpath,但通过两次纪念币预约,我发现该元素的 Xpath
是随纪念币更改的,故每次要提前进入该网址获取本次预约的 Xpath。
将所有配置文件放在general_settings.py方便管理
1 2 3 4 5 6 7 8 9 10 "../driver/chromedriver.exe" )"https://eapply.abchina.com/coin/Coin/CoinIssuesDistribution?typeid=202301" '/html/body/div[5]/div[2]/table/tbody/tr[5]/td[4]/input[1]'
1 2 3 4 5 6 7 8 9 10 11 12 13 def welcome_page ():""" 欢迎页面 :return: None """ '//*[@id="I128"]/button[1]' ).click()
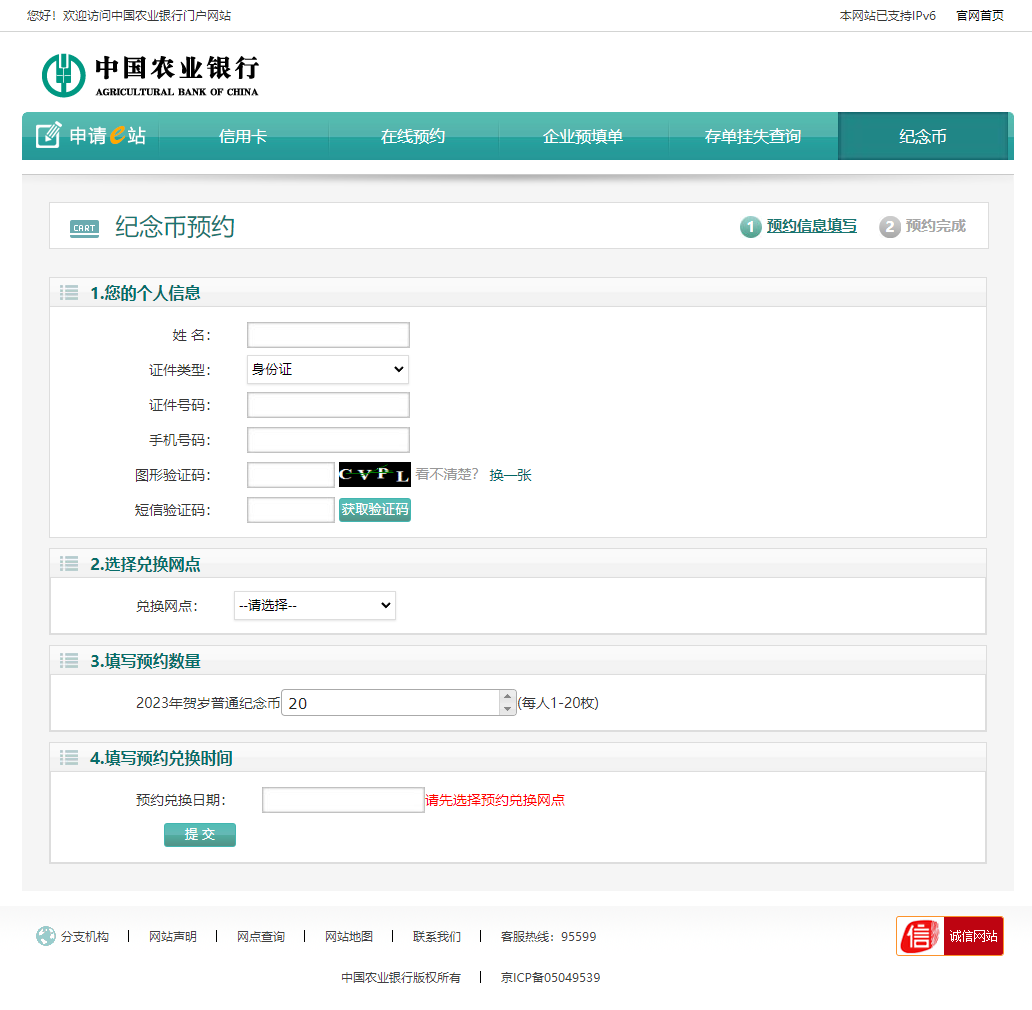
接下来,进入今天我们的主战场,布局如下:
booking_main
我将此页面分为如下五个部分:
基本个人信息(姓名、证件号码、手机号码)
图形验证码
短信验证码
兑换网点
兑换时间
其中,1、4、5 在本 Part 展示,2、3 将在下文展示。
1. 基本个人信息
由于本次自动化是多线程同时进行,且为了个人信息安全和后期再有纪念币预约可以直接使用,故将个人信息放入
MySQL 数据库中,使用 Python 第三方库 pymysql 获取数据库信息并填写。
1 2 3 4 5 6 7 8 9 "" 3306 "" "" "" ""
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def info_get (host: str , port: int , user: str , password: str , database: str , table: str ):""" 通过 MySQL 数据库获取信息 :param host: 主机名(IP) :param port: 数据库端口 :param user: 数据库用户名 :param password: 数据库密码 :param database: 信息所在 database :param table: 信息所在 table :return: 信息的元组 """ f'SELECT * FROM {table} ;' )return info_mysql
1 2 3 4 5 6 7 8 9 10 11 def fill_info (info: tuple ):""" 填写信息函数 :param info: 信息元组 :return: None """ '//*[@id="name"]' ).send_keys(info[1 ]) '//*[@id="identNo"]' ).send_keys(info[2 ]) '//*[@id="mobile"]' ).send_keys(info[3 ])
2. 兑换网点
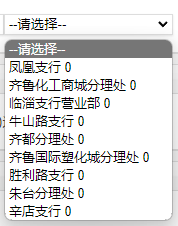
兑换网点是一个下拉框对象,可以使用 Selenium 中 Select
函数对网点进行选择。省行、分行、支行都很顺利,但营业处选项遇到了一些问题,营业处的文本为
“营业处 +
当前剩余纪念币数”,若使用select_by_index会导致不知道默认选择的营业处是否还有纪念币。
problem_place
故做以下修改:先选择默认营业处,若默认营业处剩余纪念币数 <=
20,则对营业处的列表进行遍历,选择剩余纪念币数 >= 20
的营业处,若都没有剩余,则输出 “ 该营业处没有剩余纪念币
”。当然,你也可以再对支行、分行甚至省行(只要你能跑)的列表进行遍历,选择有剩余的营业处。
1 2 3 4 "" , "" , "" , 4 ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def choose_place (province: str , city: str , country: str , default_bank_index: int ):""" 选择兑换网点 :param province: 省行名称 :param city: 分行名称 :param country: 支行名称 :param default_bank_index: 默认营业处序号(从 1 开始为第一个营业处) :return: None """ '//*[@id="orglevel1"]' ) '//*[@id="orglevel2"]' ) '//*[@id="orglevel3"]' ) '//*[@id="orglevel4"]' ) "\n" )" " )if int (default_coin_number[1 ]) >= 20 :else :for bank_index in range (1 , len (bank_arr)):" " )if int (coin_number[1 ]) >= 20 :break else :print (f"进程{thread_index} 没有营业厅有纪念币了..." )break
3. 兑换时间
选择时间可以通过两次定位来实现,但是速度较慢且 Xpath
路径不好写,且有时会涉及到 frame ,此时需要切换
frame,比较麻烦。所以本文使用 js 来处理时间控件,实现原理为删除 input 的
readonly 属性,直接输入日期。
1 2 3 4 5 6 7 8 9 10 11 12 def coin_date (coindate: str ):""" 选择兑换时间 :param coindate: 兑换时间 :return: None """ 'document.getElementById("coindate").removeAttribute("readonly");' 'coindate' ).clear() 'coindate' ).send_keys(coindate)
至此,基本的 Selenium
自动化已经完成。接下来,就是本文的核心:图像验证码与短信验证码。
Part II:图形验证码
1. 图形验证码数据集获取
既然选择用深度学习识别验证码,首先就是获取验证码数据集。
pic_captcha_url
在预约界面查找元素可知验证码的
src,刷新后会显示不同的图形验证码,这样图形验证码的数据源就搞定了。下面就是使用
requests 库爬取图形验证码,并以二进制方式写入到本地文件,这里一共爬取
3000 张验证码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import timeimport osimport requestsf'https://eapply.abchina.com/coin/Helper/ValidCode.ashx' if not os.path.exists('./pic_captcha' ):'./pic_captcha' )for index in range (3000 ):f'./pic_captcha/captcha_{index} .png' with open (file, 'wb' ) as f:print (f'captcha_{index} finished...' )0.1 )
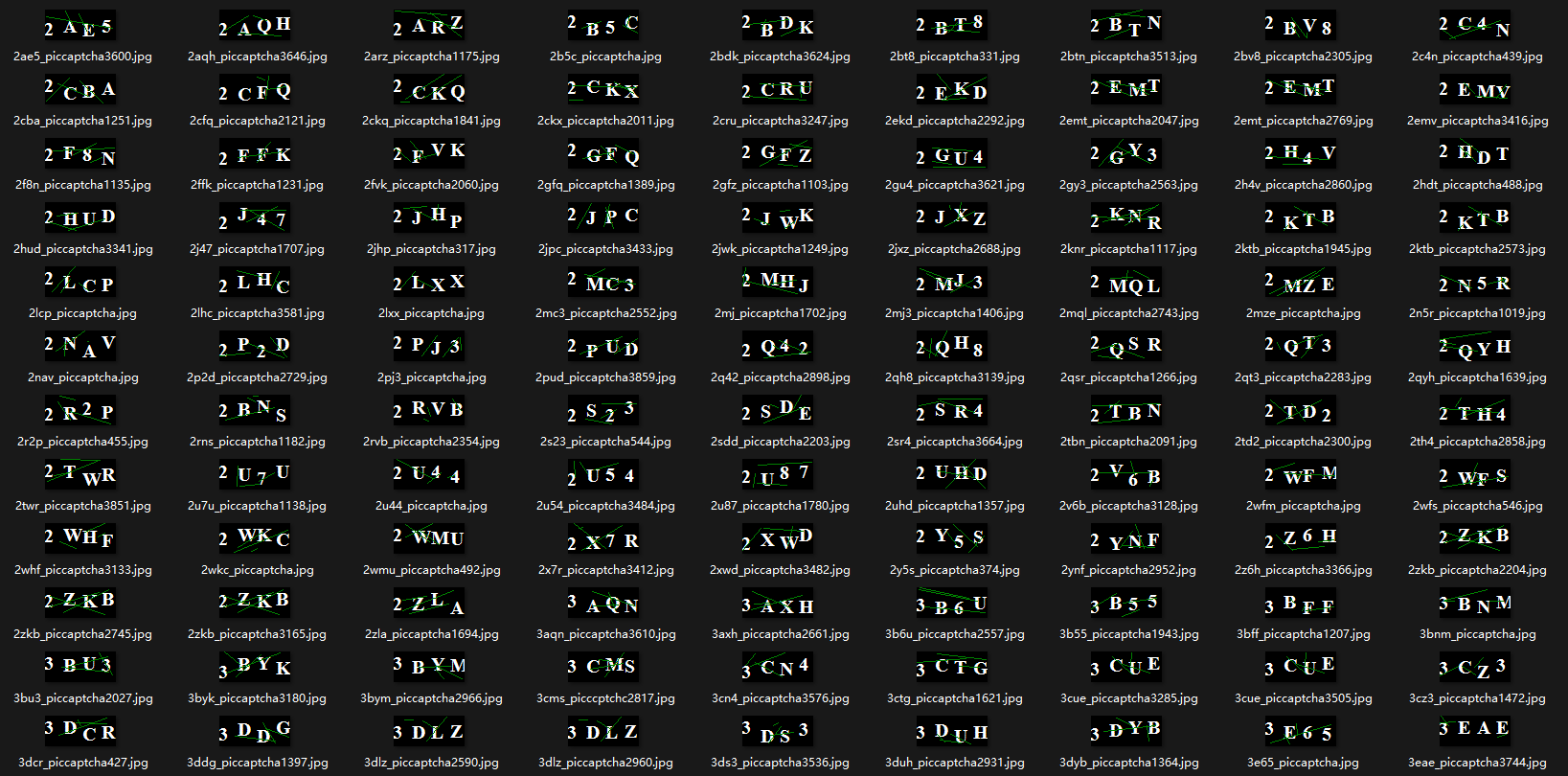
但由于这些验证码之后还需要进行标注,比较麻烦,特此将我用 2captcha
标注好的 3000 张验证码贴出来,格式为 " 验证码_piccaptcha+hash.png
"。(别问我为什么不直接用 2captcha,因为一个验证码要 5
s,这速度还不如直接手动输入)
pic_captcha
下载数据集
- Kaggle
下载数据集
- AliCloud
2. 训练模型
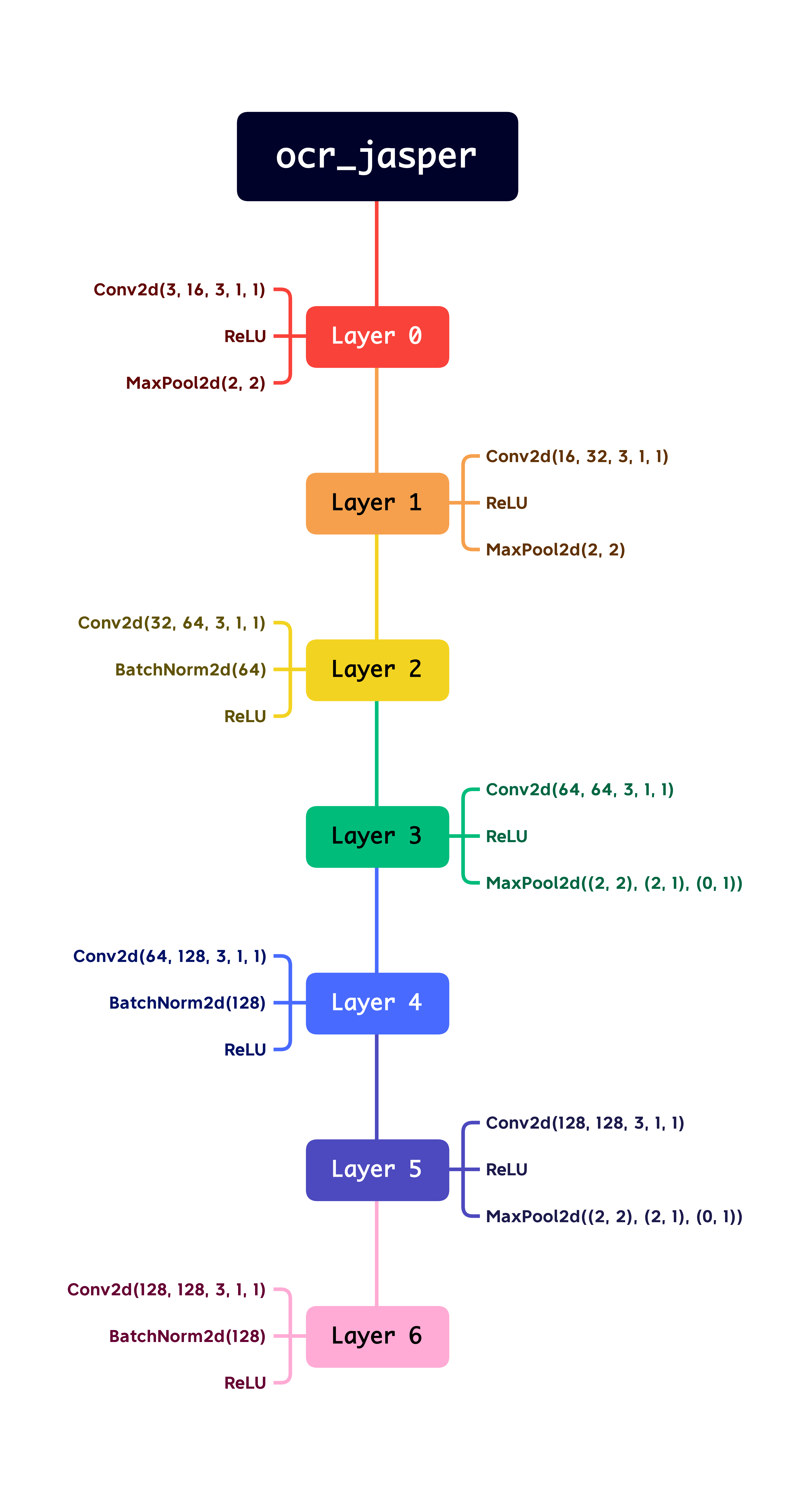
下面介绍本文采用的 CNN 模型 ocr_jasper,基于 mobildenetv2
修改而来,下图为网络结构。
ocr_jasper_network
训练代码在此就不详细说明了,详情可看仓库中 ” ocr_jasper_train “ 内的
README.md 。训练完成后,会得到 model.onnx 和
charsets.json
两个文件,分别为模型文件和字符集文件,这两个文件需配合 ocr_jasper
库使用。
3. 获取页面中图形验证码
上文爬取验证码时提到过,图形验证码的数据源是一条链接,所以无法直接通过链接直接下载图形验证码,故对图形验证码的元素进行截图并保存,方便
ocr_jasper 调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def pic_captcha_save ():""" 定位验证码进行截图 :return: None """ '//*[@id="piccaptcha"]' ) open (BytesIO(image_data)) f'./Captcha/pic_captcha_thread{thread_index} .png' )
4. 使用 ocr_jasper
识别图形验证码
现在,就可以通过调用 ocr_jasper 来对图形验证码进行识别了,ocr_jasper
可以从本文的仓库中获取,在 CMD 或 Anaconda Prompt 中运行:
1 pip install {ocr_jasper}
接下来就可以在代码中调用 ocr_jasper
了,将代码中import_onnx_path和charsets_path修改为训练好的模型和字符集文件的相对或绝对路径,默认放在项目根目录下的
Models 文件夹中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def pic_captcha_recognition ():""" 使用 ocr_jasper 识别图形验证码 :return: None """ './Models/model.onnx' ,charsets_path="./Models/charsets.json" )with open (f'./Captcha/pic_captcha_thread{thread_index} .png' , 'rb' ) as f:'//*[@id="piccode"]' ).send_keys(captcha_recognized) def get_text_captcha ():""" 获取短信验证码 :return: None """ '//*[@id="sendValidate"]' ).click()
5. 判断图形验证码是否识别正确
有时 ocr
会抽风,无法正确识别图形验证码,在此添加一个函数来判断是否识别正确。当识别错误时,id
为 errorCaptchaNo的元素会变成 ” 图形验证码错误
“;识别正确时,会变为 ” 短信验证码已发送成功
“,所以可以通过该元素文本长度来判断图形验证码是否识别正确。又因为captcha_success变量会跨函数多次调用,故将其定义为全局变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def captcha ():""" 判断图形验证码是否正确 :return: None """ global captcha_successwhile True :1 )0.5 )'//*[@id="errorCaptchaNo"]' ).textif len (is_captcha_error) == 7 :'//*[@id="piccaptcha"]' ).click() '//*[@id="piccode"]' ).clear()elif len (is_captcha_error) == 10 :True break
Part III:短信验证码
安卓系统获取手机短信验证码的方式有多种,可以通过短信数据库mmssms.db(需
root)或其他第三方平台进行获取,本文选择 adb 手机截屏 + ocr_jasper
识别的解决方案。(尊贵的 iOS 用户请自行解决本 Part)
1. 截图并裁剪短信验证码
在电脑上装好对应的手机驱动,手机打开开发者模式并开启 USB
调试,将手机通过 adb
连接到电脑后,可通过adb devices查看是否连接成功。
1 2 3 4 5 6 7 1550 1620 125 345
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def text_captcha_save ():""" 保存验证码的屏幕截图并裁剪验证码 :return: None """ f'./Captcha/text_captcha_tmp{thread_index} .png' 'adb shell screencap -p > ' + text_captcha_path)with open (text_captcha_path, 'rb' ) as f:b'\r\n' , b'\n' )with open (f'./Captcha/text_captcha_tmp{thread_index} .png' , 'wb' ) as f:f'./Captcha/text_captcha_tmp{thread_index} .png' )f'./Captcha/text_captcha_{thread_index} .png' , cropped_image)
2. 使用 ocr_jasper
识别短信验证码
和上文一样,调用 ocr_jasper
识别短信验证码,但本次不需要指定import_onnx_path和charsets_path,因为
ocr_jasper 内置了一个通用模型,对数字识别准确率接近
100%,而上文不使用内置模型的原因是此模型还包括 Unicode
编码中的所有汉字,会对图形验证码识别准确率有较大影响。
1 2 3 4 5 6 7 8 9 10 11 12 def text_captcha_recognition ():""" 短信验证码识别 :return: None """ True )with open (f'./Captcha/text_captcha_{thread_index} .png' , 'rb' ) as f:'//*[@id="phoneCaptchaNo"]' ).send_keys(captcha_recognized)
3. 信息提交
1 2 3 4 5 6 7 8 def info_submit ():""" 提交信息函数 :return: None """ '//*[@id="infosubmit"]' ).click()
Part IV:主进程函数与多线程
由于全局变量跨文件使用比较麻烦,故将上述代码封装到主进程函数main_func函数中,结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 def main_func (thread_index: int , place: list , date: str , input_enable: bool ):""" 主进程 :param thread_index: 进程序号 :param place: 预约地址列表 :param date: 预约时间 :param input_enable: 是否为最后一个进程 :return: None """ global captcha_successdef welcome_page ():def info_get (host: str , port: int , user: str , password: str , database: str , table: str ):def fill_info (info: tuple ):def choose_place (province: str , city: str , country: str , default_bank_index: int ):def coin_date (coindate: str ):def pic_captcha_save ():def pic_captcha_recognition ():def get_text_captcha ():def captcha ():def text_captcha_save ():def text_captcha_recognition ():def info_submit ():try :0 ], place[1 ], place[2 ], place[3 ])3 )except Exception as e:print (e)if input_enable:input ()
既然是 Selenium
自动化调试,就要充分发挥多线程的优势,但由于短信验证码只能挨个获取,所以在此项目中以短信验证码成功发送作为下一个进程开始的标志。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 False for current_thread in range (general_settings.threads):if current_thread == general_settings.threads - 1 :True while True :if captcha_success:1 )False break else :0.1 )
结语
以上就是本次自动化测试预约纪念币的所有内容了,如果你喜欢我,欢迎关注我的
CSDN 、知乎 ,或者在下方留下你的评论,Bye!